I’m trying to understand how GPTHuman AI review works, what it actually evaluates, and how reliable its feedback is compared to a real human reviewer. I used it on my content and got mixed results that don’t fully make sense to me. Can someone explain how this review system is supposed to be used and how to interpret its ratings for quality and accuracy?
GPTHuman AI review, from someone who got a bit too nerdy with it
GPTHuman’s home page throws this line in your face: “The only AI Humanizer that bypasses all premium AI detectors.” I went in pretty skeptical, and after a few rounds with it, I do not buy that line at all.
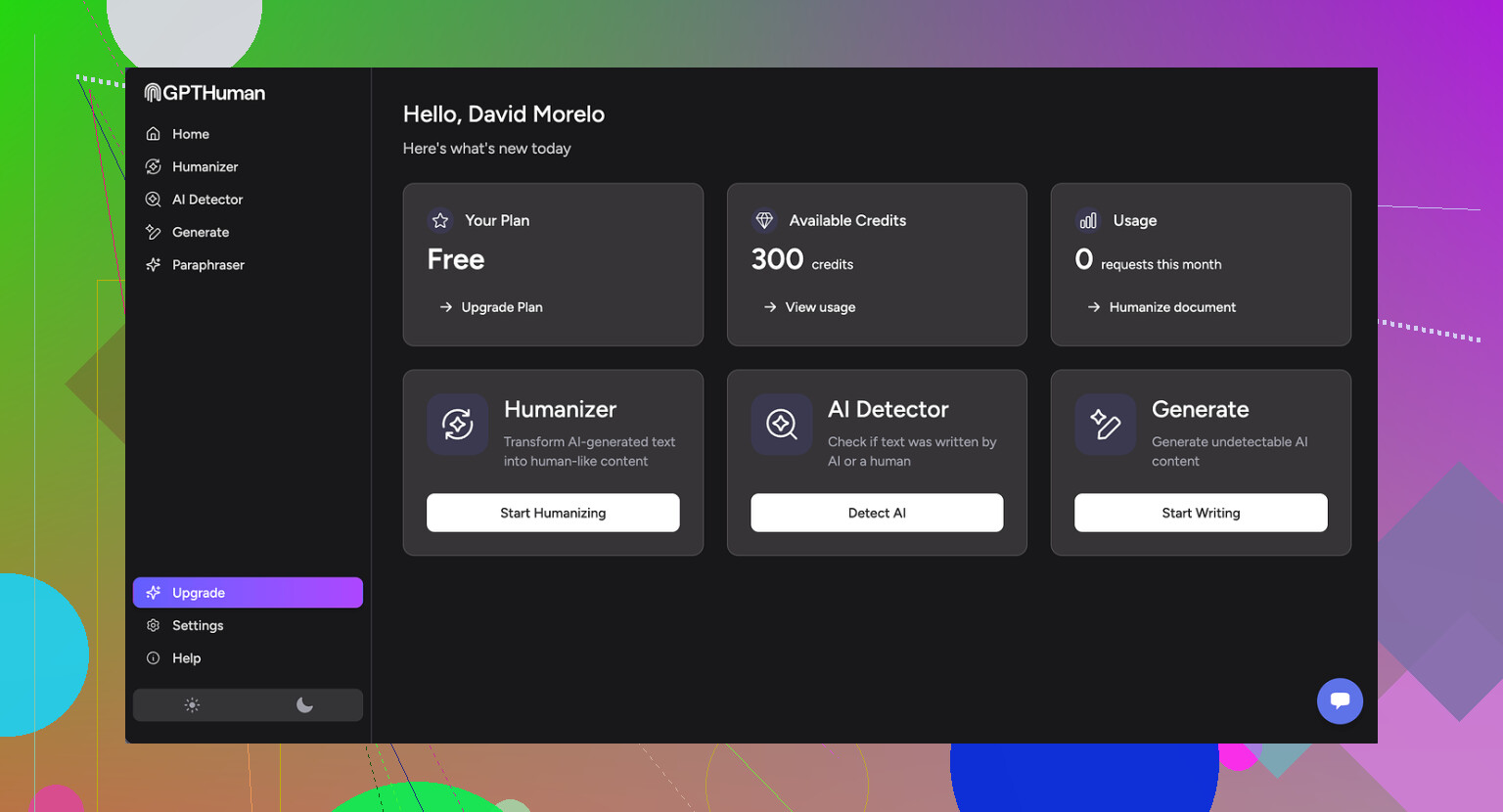
I ran three different samples through GPTHuman, then pushed those “humanized” outputs into a few popular detectors:
• GPTZero flagged every single one of the outputs as 100% AI. All three. No borderline scores, it hard-called them AI.
• ZeroGPT was a bit more mixed. Two of the samples slid through at 0% AI, which looked nice on paper, but the third one came back around 30% AI. Not amazing if your goal is staying off radar every time.
GPTHuman itself shows a “human score” after it rewrites your text. Those scores looked good, higher than I expected, but they did not line up with what the external tools said. So you end up with this split reality where the internal meter says “you are safe” while GPTZero thinks you pasted straight from a model window.
On top of that, the writing quality from GPTHuman was rough in my tests. Not unusable, but rough.
Stuff I kept seeing:
• Subject and verb not agreeing, especially in longer sentences.
• Sentences chopped off in ways that felt like the tool ran out of gas mid-thought.
• Word swaps that did not fit the rest of the sentence. It looked like a thesaurus got drunk.
• Some closing paragraphs that were nearly unreadable. I had to re-edit those by hand to figure out what the thing was even trying to say.
The structure, to be fair, stayed tidy. Paragraphs looked fine, formatting was okay. It is the sentence-level grammar where it fell apart for me.
Now the part that annoyed me more than the writing
The free tier is tiny. You get about 300 words total before it kicks you out. Not 300 words per run, 300 words across your whole account.
I hit that cap so fast that I ended up making three separate Gmail accounts to finish my usual round of tests. It felt silly. If you want to evaluate the tool properly, that free tier is not enough.
Pricing at the time I checked:
• Starter plan: from $8.25 per month if you pay yearly.
• Unlimited plan: $26 per month.
The “Unlimited” label is a bit misleading. You can run as many tasks as you want, but a single output is still capped at 2,000 words per run. So if you have a 5,000 word document, you split, copy, paste, repeat. Not the end of the world, but it adds friction.
Some policy details that matter if you care about privacy and control:
• Purchases are non-refundable. Once you pay, that money is gone.
• Your text goes into their training data by default. You have to opt out if you do not want that.
• They keep the right to use your company name in their marketing unless you tell them not to.
So if you write for clients or deal with internal docs, you need to think about both the training thing and the name usage thing, or go dig through their settings and support to shut that off.
How it stacked up against other “humanizers”
I tried GPTHuman next to Clever AI Humanizer during the same session, with the same base text. That way I did not give either one an advantage.
Clever AI Humanizer did better for me in two areas:
• Detector scores: on the same sample text, it held stronger scores across the external tools. I had fewer “100% AI” hits there.
• Access: it was fully free to use when I tested it, no tiny 300 word ceiling to trip over.
Link to the thread where I first saw it tested is here:
If you are still in the phase where you are just trying to see what works with your own writing style and your own detectors, starting with something free felt less frustrating than constantly hitting GPTHuman’s wall and juggling multiple emails.
If you care about practical stuff
What I would do if I were in your place:
• Do not trust any built-in “human score” alone. Always double-check with external detectors like GPTZero and ZeroGPT.
• Run at least three different samples of your typical content. Short form, long form, different tones. GPTHuman behaved differently across them.
• Read every output line by line before you share it. GPTHuman’s grammar slips are easy to miss if you skim.
• Look at the terms before you upload anything sensitive. Opt out of training if that matters to you, and tell them not to use your company name if that bothers you.
• If you write longer pieces, factor the 2,000 word limit into your workflow. Batch your content or you will be stuck splitting mid-argument.
My takeaway after using it across those runs: it works as a noisy rewriter, but I would not rely on it if your goal is reliable AI detection avoidance plus decent grammar in one shot. You will still end up editing by hand and juggling detector scores on your own.
1 Like
Short version. GPTHuman “AI review” is mostly a detector-style heuristic plus a rewrite layer. It is not a substitute for a human editor, and its scores do not map cleanly to other detectors or to real reader judgement.
Here is how it seems to work and what it evaluates, based on your experience plus tests like the ones from @mikeappsreviewer:
-
What GPTHuman AI review is likely checking
From the behavior and outputs, it looks like it focuses on things detectors usually look at:
• Token patterns and repetition.
• Sentence length variance.
• Word choice randomness and rarity.
• Basic structure patterns common in LLM text.When it shows you a “human score”, it is scoring how far your text is from its internal AI-ish profile. That metric is internal. It does not reflect GPTZero, ZeroGPT, or other tools. So mixed results between them are expected, not a bug.
-
Why its feedback feels “off” vs a real human
A real human reviewer evaluates:
• Clarity.
• Argument strength.
• Audience fit.
• Tone consistency.
• Factual issues.
• Style and voice.GPTHuman AI review gives you a number and some surface-level changes. It does not understand your intent, your brief, or your audience. So it can say “high human score” while:
• The argument is weak.
• The tone does not match your brand.
• The flow is broken.It optimizes for detector evasion, not for human editorial quality.
-
Reliability vs detectors and vs humans
From what you described and from @mikeappsreviewer’s tests:
• Internal “human score” often conflicts with GPTZero.
• ZeroGPT sometimes aligns, sometimes not.
• Detectors themselves are inconsistent with each other.
• None of them are a solid proxy for human quality.So if your question is “Is GPTHuman AI review as reliable as a human editor?” the answer is no.
If your question is “Does the GPTHuman score predict what GPTZero will say?” also no. -
How to use it without losing your mind
Treat it as a noisy hint system, not a judge. Some practical steps:
• Start with your own quality checks first. Read your piece out loud. Fix clarity, structure, and logic before touching any humanizer.
• Run GPTHuman AI review, note the score, but do not trust it alone.
• Cross test your content on at least one external detector you actually care about, usually the one your client or school uses.
• If the text reads worse after humanization, revert, then only borrow small phrasing tweaks. Do not accept full rewrites blindly. -
When it makes sense to ignore GPTHuman completely
I would skip relying on it in these cases:
• Academic or compliance sensitive content, where detection is high risk. Detectors change, terms change, and no tool gives guarantees.
• Brand voice heavy content, like website copy or email sequences. Its rewrites often break tone and create weird word choices.
• Long form where flow matters, because splitting into 2,000 word chunks can wreck continuity.In those cases, a human editor or at least a good LLM with explicit style instructions will outperform an automated “humanizer”.
-
How it compares to alternatives
GPTHuman is one more tool in the “text randomizer” bucket.
From my tests, plus what you and @mikeappsreviewer saw:
• It tends to over-risk grammar and coherence to chase detector-friendly patterns.
• The internal score encourages a false sense of safety.
• The low free limit makes it hard to evaluate properly.If you want to experiment with this type of tool without hitting a 300 word wall, Clever Ai Humanizer is worth a look. It tends to produce cleaner sentences, plays a bit nicer with external AI detectors in many cases, and is friendlier for testing different tones and lengths. Still not a human editor, but less painful to iterate with.
-
A simple workflow that balances all this
If your goal is better content plus lower detection risk:
• Write the piece yourself, or draft with an LLM, then heavily personalize. Add your own stories, opinions, and small errors.
• Run a grammar and clarity pass with a regular editor tool, not a humanizer.
• If you must lower AI scores, send problem sections through something like Clever Ai Humanizer in small bits, then hand edit the output so it matches your normal voice.
• Recheck with the same external detector your stakeholders use.
• Stop once the text reads natural and the risk level is acceptable. Chasing 0 percent “AI” often breaks quality.
Bottom line. Treat GPTHuman AI review as a rough filter, not a trusted reviewer. For real editorial judgement, a human or a careful manual editing workflow will beat its scores every time.
You’re not crazy, the “mixed results” are kind of baked into how GPTHuman is set up.
What it’s actually doing in that “AI review” step is closer to a detector-style pattern check than a real editorial review. It’s basically sniffing for:
- Super-regular sentence lengths
- Very “safe” word choices and repetition
- Predictable structure and transitions
- Low randomness in phrasing
Then it spits out a “human score” that reflects how far your text deviates from its idea of “LLM-ish.” That’s why you can get a shiny 90+ score in GPTHuman and still have GPTZero scream 100% AI. Their internal profile just doesn’t map to what external tools look for.
Where I slightly disagree with @mikeappsreviewer and @voyageurdubois is on one point: I don’t think GPTHuman is only useful as a noisy rewriter. If you ignore the “bypass all detectors” marketing and treat the score as a directional hint, it can be useful in a narrow way:
- It’s decent at telling you when your text is too “smooth” or repetitive, which is exactly how a lot of AI drafts read.
- Its low “human score” usually correlates with that very bland, over-polished tone, even if other detectors disagree on the AI label.
So in terms of editorial value compared to a real human:
- It does not evaluate argument quality, nuance, or audience fit.
- It barely touches factual accuracy.
- It sometimes actively harms tone and coherence when it rewrites.
That’s why its “feedback” feels off. It’s not actually saying “this is good writing,” it’s saying “this text looks less like the pattern I associate with AI.” Totally different goal.
How I’d interpret GPTHuman’s review in practice:
- If it gives you a low score: your text is probably too uniform, safe, or generic. That’s a good nudge to add personal details, concrete examples, and your own quirks.
- If it gives you a high score but the writing now sounds weird: trust your eyes, not the meter. Its heuristic is happy to trade grammar and flow for “randomness.”
So reliability vs a real human reviewer:
- Human editor: looks at logic, clarity, impact, voice, and context.
- GPTHuman: looks at pattern irregularity and surface randomness.
Those are not interchangeable. If your main concern is “does this sound like me and does it persuade?” then GPTHuman is almost irrelevant. If your concern is “can I nudge my text away from obvious AI patterns a bit?” then it’s a rough tool in the toolbox, nothing more.
Given you already got conflicting detector results, I’d do this:
- Stop chasing a perfect “pass” on every tool. They already disagree with each other.
- Use any AI review (GPTHuman or otherwise) as a weak signal: if multiple tools and your own gut say “this feels robotic,” then revise for voice and specificity.
- For cleaner rewrites and less grammar chaos, something like Clever Ai Humanizer tends to keep sentences more readable while still breaking up the obvious AI cadence. You’ll still need to edit, but you won’t be untangling as many broken sentences.
Short version: GPTHuman’s AI review is a pattern meter, not a human brain. Treat its score like a weather forecast, not a verdict. If the output reads worse after “humanization,” that’s your answer right there.